

A Dipsec, uma agência de inteligência artificial chinesa recentemente conhecida, após a discussão da indústria de tecnologia, fez uma conversa depois de criar uma série de grandes modelos de idiomas depois de superar muitos dos principais desenvolvedores de IA do mundo.
A DePSec lançou seu boato de grande idioma, R1 em 20 de janeiro. O assistente de IA atingiu o número 1 na Apple App Store nos últimos dias, a conversa longa dominante da abertura caiu para o número 2.
Sua repentina dominação – e a capacidade de superar os principais modelos dos EUA em vários critérios – ambos têm O Vale do Silício é um frenesi transmitidoEspecialmente porque a empresa chinesa relatou que seu modelo foi desenvolvido em uma fração de despesas.
Choque nos círculos tecnológicos dos EUA Provocou uma contagem no setor, É mostrado que os desenvolvedores de IA não precisam de dinheiro e recursos extras para melhorar seus modelos. Em vez disso, os pesquisadores percebem que esses processos podem ser implementados, tanto no uso de custos quanto em energia, sem nenhum compromisso.
O modelo anterior do R1 chegou à base da V3, lançada no final de dezembro. No entanto, na segunda-feira, o DIPSEC publicou outro modelo de IA de alto desempenho, Janus-Pro-7b, que é multimodal que pode processar diferentes tipos de mídia.
Aqui estão alguns recursos que fazem com que os grandes modelos de idiomas do diploma pareçam tão únicos.
Tamanho
Apesar de desenvolver uma pequena equipe com menos fundos do que os principais gigantes da tecnologia americana, a DePSec está subornando com um modelo grande e forte acima do seu peso que combina bem com os baixos recursos.
Isso ocorre porque o assistente de IA depende de um sistema “especialista da mistura” para dividir seu grande modelo em inúmeros pequenos submódios ou “especialistas” ou “especialistas” Especialista para lidar com um certo tipo de tarefa ou dados com todos. Ao contrário do método tradicional das marés, que usa cada parte do modelo para cada entrada, cada submodal só é ativo quando seu conhecimento específico é relevante.
Assim, embora a v3 tenha um total de 671 bilhões de parâmetros ou configurações no modelo de IA que aprendeu que está realmente usando apenas 37 bilhões de uma vez, de acordo com um Relatório Técnico Seus desenvolvedores são publicados.
A empresa também desenvolveu uma estratégia exclusiva de suporte de carga para garantir que qualquer especialista não esteja subarregado ou subcarregado usando uma consistência mais dinâmica, em vez de uma abordagem baseada em fino baseada na empresa que pode levar a um desempenho ruim.
Todos eles permitem que o DIPSEC nomeie uma equipe poderosa de “especialistas” e adicione mais todo o modelo sem desacelerar todo o modelo.
Ele também usa uma técnica chamada escala de computação em tempo de infecção, que permite que o modelo se ajuste aos seus esforços de contagem acima ou abaixo da tarefa, em vez de executar energia total. Por exemplo, apenas algumas engrenagens metafóricas podem ser necessárias em uma pergunta direta, onde todo o modelo solicita uma análise mais complexa pode ser usada.
Juntos, essas técnicas facilitam o uso de um modelo tão maior de uma maneira muito mais eficiente do que nunca.
Gasto de treinamento
O design do diPcsic é mais barato que seus concorrentes e o torna mais rápido para o treinamento.
Até as principais agências de tecnologia dos Estados Unidos estão gastando bilhões de dólares por ano na IA, a DePSec alegou que a V3 – que funcionava como base para o desenvolvimento de R1 – era inferior a milhões de dólares e apenas dois meses para serem construídos. E devido à proibição de exportação dos EUA na qual o Nvedia H1 100 limitou o acesso limitado a chips de computação de IA, a Dipsec Nvidia foi forçada a criar seus modelos com H800 menos poderoso.
Um dos maiores progressos da organização é o desenvolvimento de uma estrutura de “precisão mista”, que usa uma combinação de número de ponto flutuante de 32 bits (FP32) e número de 8 bits de baixa prioridade (FP8). O último usa baixa memória e é mais rápido para processar, mas pode ser menos preciso.
Em vez de confiar em um ou outro, o DePSEC salva memória, tempo e dinheiro usando o FP8 para a maioria dos cálculos e a mudança para o FP32 para algumas das principais atividades em que a precisão é universal.
Alguns no campo observaram que recursos limitados provavelmente forçaram o DIPSEC a inventar um caminho que possam provar que os desenvolvedores de IA podem fazer mais com menos.
Desempenho
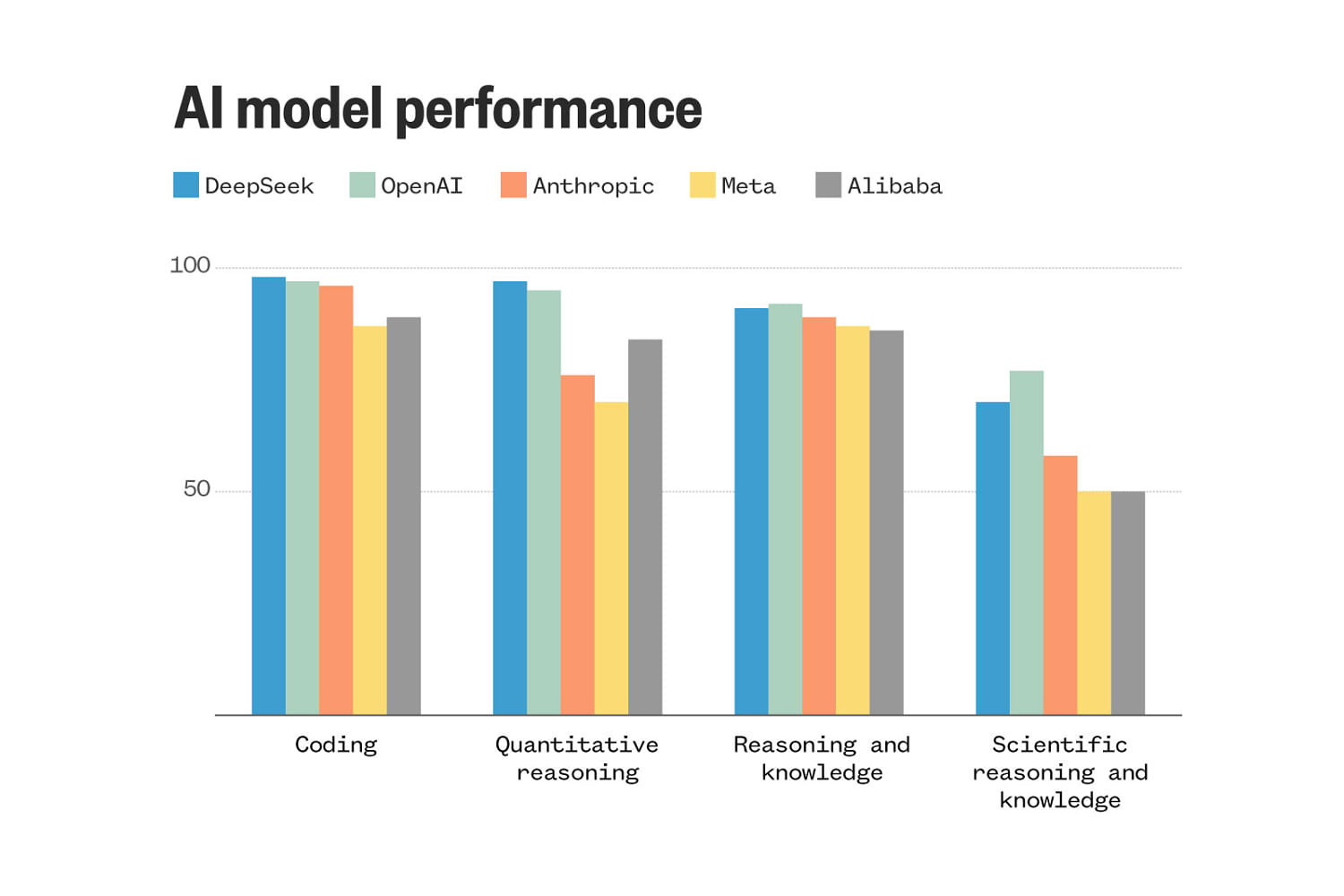
Apesar da maneira relativamente modesta, a pontuação dos critérios do DIPSC está alinhada com o mais recente modelo de corte dos desenvolvedores de IA dos Estados Unidos.
R 1 quase com pescoço e pescoço, incluindo o OpenAi e 1 modelo O indicador de qualidade de análise artificialRanking para uma análise de IA distinta. O R1 já está atingindo o GEMI 2.0 Flash do Google, o Anthropic CLOD 3.5 Sonnet, o Meta’s Lama 3.3-70B e o GPT -4O do OpenAI.
Uma de suas principais características é a capacidade de explicar seu pensamento por meio do argumento de reflexão, que se destina a dividir as tarefas complexas em pequenas etapas. Esse método permite que o modelo volte e corrija as etapas anteriores – duplica o pensamento humano – permite que os usuários sigam a lógica.
V3 também foi Desempenho igual CLOD 3.5 Sont Sont depois de publicar no mês passado. O modelo que foi realizado anteriormente foi o GPT-4O, o LAMA 3.3-70B e o Alibaba Qwen2.5-72B, terceirizam o modelo anterior de IA da China.
Enquanto isso, Depsek Alegar Seu novo Janus-PO-7B superou a abertura da abertura e 3 meios de propagação estável em vários critérios.

















{kind=link}